
As a big fan of open large language models (LLMs) like the Gemma and Qwen series, I'm always interested in new developments in the space of open LLMs.
Running these models on your own system with tools like Ollama or LM Studio offers incredible benefits, from 100% privacy to cost savings. That's why I was particularly excited by a recent announcement at Google I/O: Gemma 3n.

Course
Local LLMs via Ollama & LM Studio - The Practical Guide
Learn how to use LM Studio & Ollama to run open large language models like Gemma, Llama or DeepSeek locally to perform AI inference on consumer hardware.
Explore courseWhile, of course, many headlines focused on the latest Gemini updates and Project Astra, Gemma 3n quietly emerged as a significant step forward for open LLMs.
Because, even though it's an open model, just like its Gemma 3 predecessors, it introduces some truly innovative features that set it apart.
2 Models Baked Into 1
Unlike typical LLMs, Gemma 3n isn't just one model. It's actually a combination of two models merged into one.
Specifically, it combines a 5 billion and an 8 billion parameter model by using shared layers and parameters from the underlying neural network. In addition, Google uses various optimization techniques, which shrink the memory usage and requirements of these combined models down to the equivalent of 2 billion and 4 billion parameters, respectively.
This means you get the performance and power of 5-billion and 8-billion parameter models while only requiring the memory resources of much smaller models.
This is a game-changer, especially for running LLMs on less powerful hardware. The goal is to make these capable models accessible even on relatively low-end devices, potentially including some smartphones.
A New Architectural Approach
How did Google achieve this? The innovation lies in a new architectural approach that allows for shared layers within the neural network that powers the LLM. Certain parts of the neural network are utilized by both the 5 billion and 8 billion parameter models, while other parts are unique to each.
For application developers, this means you can essentially tell the model which version you want to use: the smaller, more efficient one, or the larger, more capable one. You can also switch to use different models "on the fly" for different prompts.
For example, for tasks like text summarization, the smaller version of Gemma 3n might be all you need. You'd get faster results without necessarily sacrificing quality. However, for content generation where the best possible quality might be needed, you could opt for the larger version.
The beauty of this approach is that you don't need to download, install, or manage separate models. Both are integrated into a single package. This saves disk space and time, allowing you to seamlessly switch between the two integrated models based on your task's requirements.
And It's Multimodal!
Another very exciting aspect of Gemma 3n is its multimodal capabilities.
It's not just limited to text input - it can also process video, audio, and images. As Google highlights, "Gemma 3n can understand and process all your text and images. It offers significantly enhanced video understanding."
This opens up a world of new possibilities. With its audio capabilities, Gemma 3n could be used to transcribe audio, create video captions, or even translate audio, all locally on your device.
Combined with its reduced memory footprint, this multimodal support could unlock brand new applications for developers and users alike.
And It's Still A Locally Running Open Model!
Gemma 3n embodies all the advantages that make open LLMs so interesting:
- 100% Privacy: Since the model runs locally on your machine, no data ever leaves your system. This is a critical benefit for sensitive tasks (especially for companies, of course).
- Cost-Effective: There are no subscription fees or per-use charges. Ignoring the cost of your hardware and electricity, you don't have to pay anything to use the model.
- Versatile Performance: For many common tasks like text summarization and content generation, open models like Gemma 3n can deliver excellent results.
As Google shared in their announcement blog post, Gemma 3n may indeed beat much larger models.
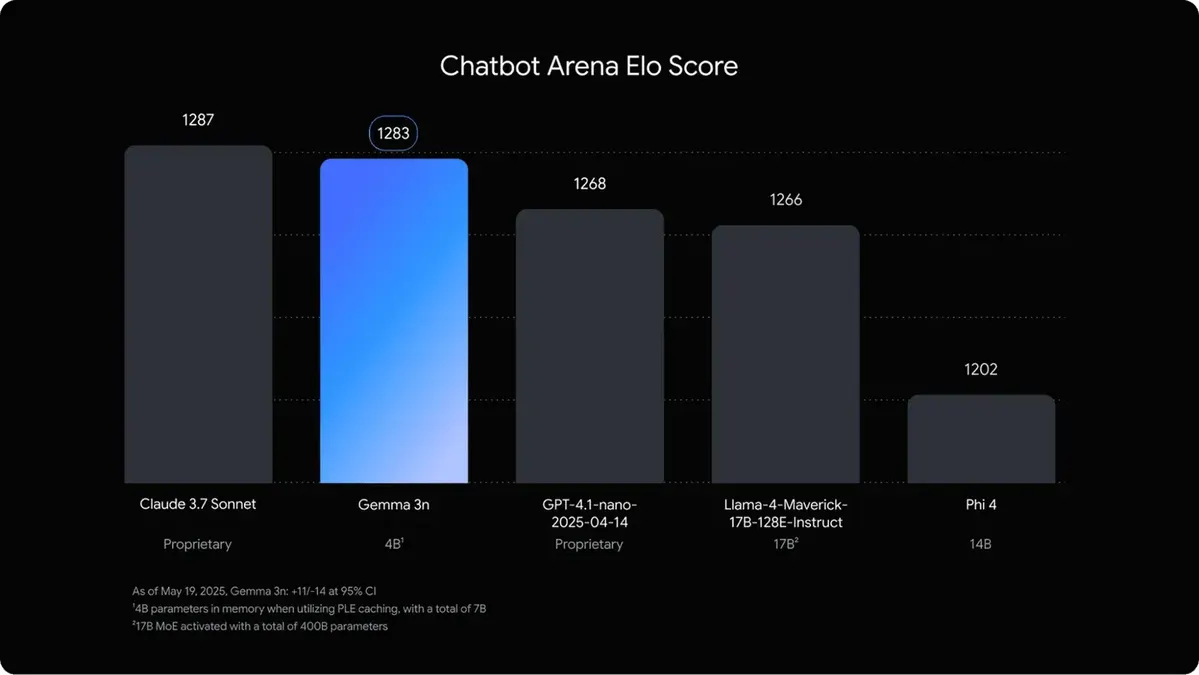
The new architecture, the two-in-one model approach, and the significantly reduced memory footprint make Gemma 3n incredibly promising for local deployment and integration into diverse applications.
I'm genuinely excited to see how this model develops and when it becomes widely available through tools like Ollama.