

You've heard about running powerful open Large Language Models (LLMs) like Llama, Gemma, or Qwen right on your own computer.
It sounds amazing - AI superpowers without relying on big tech companies!
But wait... don't these models have billions of parameters? Aren't they huge files? How could your regular laptop or desktop possibly handle that much data?

Course
Local LLMs via Ollama & LM Studio - The Practical Guide
Learn how to use LM Studio & Ollama to run open large language models like Gemma, Llama or DeepSeek locally to perform AI inference on consumer hardware.
Explore courseWell, original LLMs are indeed massive.
But there's a clever technique that makes local AI possible for almost everyone: Quantization. It's a compression technique that reduces the amount of (V)RAM those LLMs need.
The Big Problem: LLMs Need Lots of Memory
First things first - what exactly is the problem?
Think of an LLM's "brain" as being made up of billions of tiny adjustment links, called parameters. In the end, these numbers hold all the model's learned knowledge. They control which tokens the model will emit for a given input.
Originally, the setting for each knob (each parameter) is stored with high precision, like writing down a measurement as 3.14159265. Commonly used data types like Float32 (FP32), Float16 (FP16) or BFloat16 (BF16) use 4 or 2 bytes of memory for each single parameter.
Therefore, let's do some quick math: A popular 7-billion parameter model (which would be considered a very small model these days!) stored in FP16 needs:
7 billion parameters * 2 bytes/parameter = 14 billion bytes = 14 Gigabytes (GB)
That's 14 GB of (V)RAM needed just to load the model's parameters!
And those parameters must be loaded into memory because the entire model (which mostly consists of those parameters) needs to be in memory in order to run.
When you add the extra memory needed for the model to actually work (the "overhead," including remembering the conversation context), the requirement climbs even higher.
Your average laptop or even a decent gaming PC graphics card often doesn't have that much dedicated Video RAM (VRAM).
So, how do we run these models?
Quantization To The Rescue
Quantization is essentially a smart compression technique for LLMs.
The goal is simple: Reduce the amount of memory each parameter takes up, making the overall model much smaller, without significantly hurting its performance or "intelligence."
Think of it like this: You have an incredibly detailed, high-resolution photo that takes up a ton of space. Quantization is like converting it to a high-quality JPEG. You use clever algorithms to reduce the file size dramatically by storing the information more efficiently. You might lose a tiny bit of the absolute finest detail if you zoomed way in, but the picture still looks fantastic for all practical purposes.
How Does It Work (In A Nutshell)?
The main trick is swapping out those space-hungry high-precision numbers (like FP16 using 2 bytes) for much smaller, lower-precision formats. Common quantized formats include:
- INT8: 8-bit integers. These use only 1 byte per parameter - instantly cutting the model size roughly in half compared to FP16!
- INT4: 4-bit integers. These use an astonishing half a byte per parameter - making the model about four times smaller than the FP16 original!
How can we represent complex numbers with such simple integers? Quantization methods use clever mathematical tricks. Instead of just crudely rounding numbers, they often analyze ranges of values and use the limited bits smartly to represent the most important information. They figure out how to approximate the original high-precision values very effectively using far less storage.
These efficiently packed, quantized models are often saved in specific file formats designed for them. You'll often see the .gguf format mentioned - this is a very popular container for quantized models that tools like LM Studio and Ollama use heavily.
The Payoff: Why Quantization is a Game-Changer
So, why is this process so important for running LLMs locally?
- Fits on Your Machine: Suddenly, that 7B parameter model doesn't need 14GB+ anymore. An INT8 version might need ~7GB, and an INT4 version only ~3.5GB for its parameters! This often brings models within reach of consumer GPU VRAM or system RAM.
- Runs on Normal Hardware: You don't necessarily need a multi-thousand dollar AI server. Your gaming PC or modern laptop can often run surprisingly capable quantized models.
- Potentially Faster: Moving smaller amounts of data around (1 byte instead of 2 or 4) between memory and the processor can sometimes speed up how fast the model generates responses (inference speed).
The Trade-off? Reducing precision can slightly affect model quality. However, modern quantization techniques (you might see names like Q4_K_M, Q5_K_S, Q8_0 when downloading models) are incredibly good at minimizing this impact. For most tasks, a well-quantized model performs almost identically to its larger, unquantized counterpart.
Bringing It All Together
When you use amazing tools like LM Studio or Ollama to download an LLM, you'll essentially always download a quantized version. The tools take care of that.
You can tell that a model is quanitzed if it carries a name like Gemma-3-7B-Q4_K_M or has a tag like Q4_K_M in its model description.
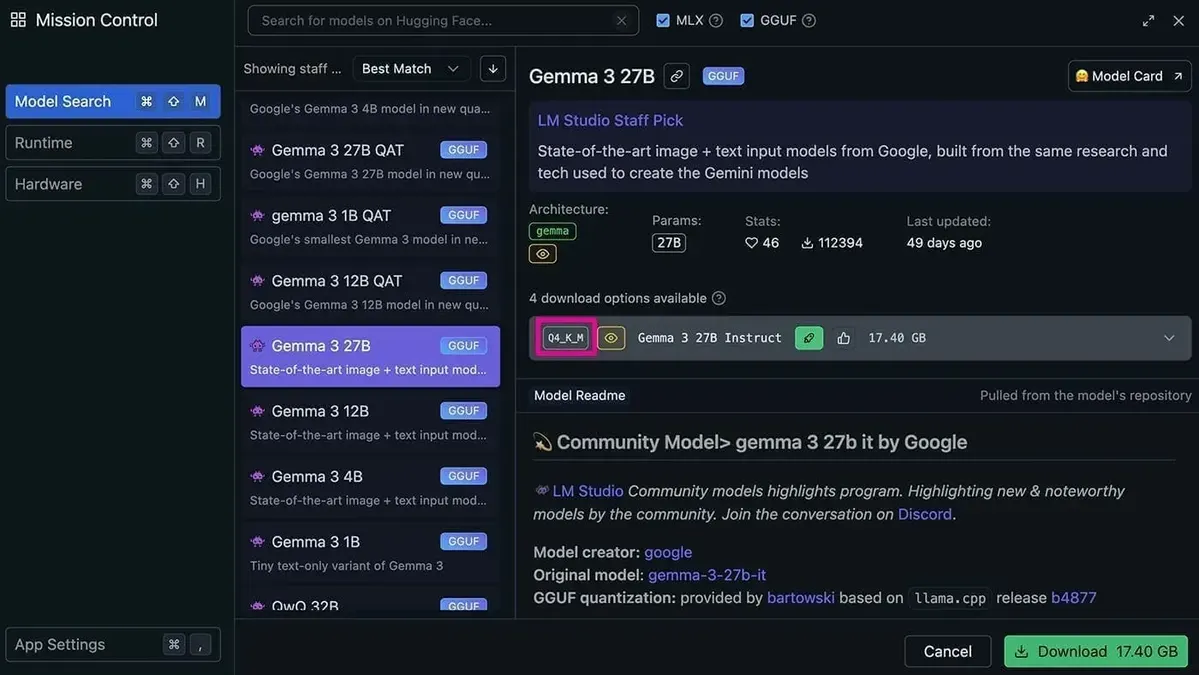
That tells you it's a quantized version! You're downloading a model that's already been put through this shrinking process, ready to run efficiently on your hardware.
So, long story short: Quantization cleverly bridges the gap between the massive scale of modern AI models and the capabilities of everyday hardware. So next time you chat with your local LLM, give a little nod to the quantization that made it possible!