
MCP - short for "Model Context Protocol" - is the new buzzword in AI-town.
As always, there's no shortage of AI-fluencers on X that will tell you that MCP-enabled opportunities are "wild", that you're "missing out", and that it "changes everything" or that it's "over for XYZ" because of MCP.
But ignore the hypebois, MCP is actually a pretty interesting concept in my opinion. And I'll let you know why.
MCP (Model Context Protocol) is a relatively new protocol that was introduced by Anthropic on November 25th, 2024.
The idea behind this protocol is to standardize the way (you could say "the language") in which LLM-powered AI tools get access to tools (like interacting with the file system, inserting data into databases, etc.) and data (e.g., fetching data from databases, web search).
How Do LLMs Use Tools?
To understand MCP (and why it's useful), it's crucial to understand that all those LLM-powered AI applications are just token generators. That was true two years ago, it's still true today. And it will be true next year, too.
Many people forgot this - or never knew, because they were too busy hyping their AI startup on X.
But that is how LLMs work: They complete token sequences. Modern reasoning models are no exception to that rule by the way - they still produce tokens to complete sequences.
So how can you give such AI applications access to tools (like web search)?
Well, in the end by using text to describe tools, describe intent to use tools and handle tool responses. The tools themselves are not generated by the LLM, though. They're provided by the application that uses the LLM.
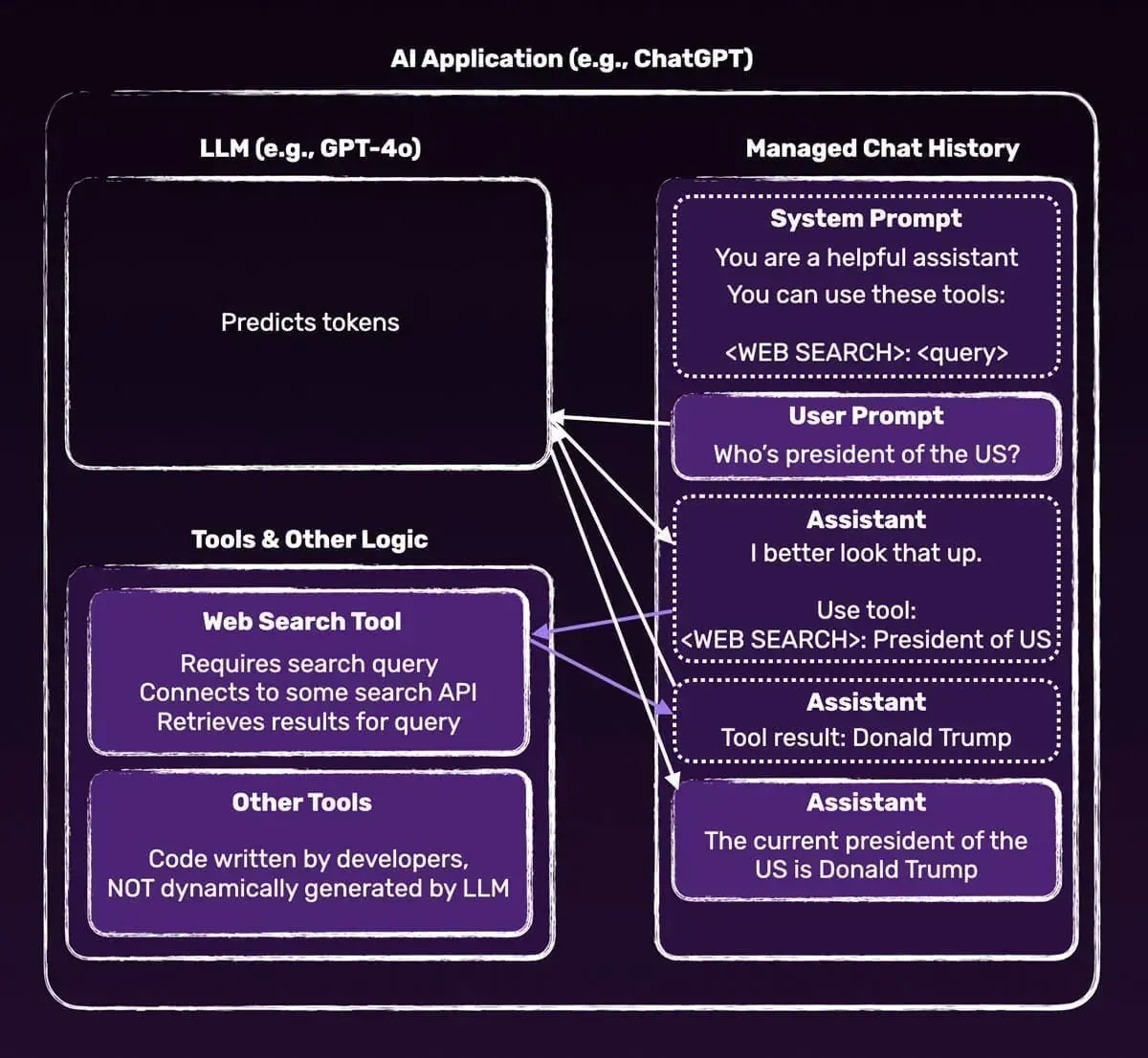
Let's take a look at those different parts step by step - beginning with the injection of tool information into the system prompt.
For example some text like this:
let history = [
{
role: 'system',
content: `
You are a helpful assistant with access to these tools which you can use if you need them to provide a meaningful response to the user query:
- Web search: Use by outputting <WEB SEARCH>: <SEARCH QUERY></SEARCH QUERY>
`,
},
];That's a bit of a simplified (and totally made up) example, but this is how ChatGPT & co work behind the scenes.
If the user then asks the AI chatbot something like Who's the current president of the USA?, because of this injected system prompt, it's likely (but not guaranteed!) that the LLM will output the tokens: WEB SEARCH: Current president of the USA.
The chat history might then look something like this:
history = [
...history,
{
role: 'user',
content: "Who's the current president of the USA?",
},
{
role: 'assistant',
content:
'<WEB SEARCH>: <SEARCH QUERY>Current president of the USA</SEARCH QUERY>',
},
];However, the AI application (e.g., ChatGPT) is built such that it will capture those special tokens (WEB SEARCH) and not show them to the user.
Instead, it'll extract the search query (Current president of the USA in this example) and execute some code (that was written by OpenAI employees and not dynamically generated by the LLM!) to perform that web search behind the scenes.
The result of that search will then be fed back into the LLM, as a continuation of the chat history. For example like this:
history = [
...history,
{
role: 'assistant',
content:
'Web search results: Donald Trump is the current president of the USA.',
},
];As a next step, the LLM will again produce tokens - now based on the chat history that includes the original system prompt, the user's original question ("Who's the current president of the USA"), and the web search results.
The tokens generated based on this chat history will likely be something like "Donald Trump is the current president of the USA". And it's then this text that's output on the screen.
Of course, the internals will differ from AI application to AI application, but this is the basic idea behind how LLM-powered AI applications can interact with tools and data.
Specifically, for example when interacting with OpenAI's AI models via their API / SDKs, you won't describe tools as outlined above. Instead, OpenAI exposes a feature called "functions" via their API.
With that feature you'd make your tools available like this:
const tools = [
{
type: 'function',
name: 'get_weather',
description: 'Get current temperature for a given location.',
parameters: {
type: 'object',
properties: {
location: {
type: 'string',
description: 'City and country e.g. Bogotá, Colombia',
},
},
required: ['location'],
additionalProperties: false,
},
},
];
const response = await openai.responses.create({
model: 'gpt-4o',
input: [
{ role: 'user', content: 'What is the weather like in Paris today?' },
],
tools,
});(also see their official documentation)
But behind the scenes, those tools ("functions") will be injected into the system prompt in some way. OpenAI will just handle all the related complexities of detecting tool use etc.
Why Do We Need MCP Then?
As the above example shows, you don't need MCPs to let AI apps use tools.
But there is a problem with approach outlined above, that may be solved by MCPs: There is no clearly defined, standard way of describing tools to LLMs.
The developers building such an AI application may choose to "tell" the LLM to output <WEB SEARCH>: ... to use the web-search tool. But they could've also chosen WS: ... or any other identifiers. It's just about producing tokens after all - so it's up to the AI app developers to choose which tokens they want the LLM to produce for a certain tool.
Therefore, different AI apps will likely use different ways of defining tools and implementing tool use. And different tools will also likely be implemented in different ways.
Why is this a problem? Because it means that every tool needs to be "hard-coded" into the app by the application owners.
If you're a developer building something that you want to be usable as a tool by AI apps (e.g., a hotel ratings search tool), you have to hope that the developers of those AI apps will implement your tool in a way that their AI apps can understand.
That's where the MCP idea can help.
MCPs Standardize How Tools Are Exposed to LLMs
MCP clearly defines how tools should be described and exposed to LLM-based applications. And they allow you, as a developer, to write all the code that controls what actually happens when a LLM wants to use the tool.
As the developer of a MCP (or a MCP server, to be precise - more on that later), you therefore describe your tool, its capabilities, and the required input (that must be generated by the LLM, for example the web search query). Most importantly, you also write the code that will run, whenever your tool is used.
Here's some example code (for a dummy tool that allows a LLM to store some knowledge in a database) showing how such a MCP server could be built with TypeScript and the official MCP SDK:
import {
McpServer,
ResourceTemplate,
} from '@modelcontextprotocol/sdk/server/mcp.js';
import { StdioServerTransport } from '@modelcontextprotocol/sdk/server/stdio.js';
import { z } from 'zod';
const server = new McpServer({
name: 'Demo',
version: '1.0.0',
});
server.tool(
'store-knowledge',
{ topic: z.string(), content: z.string() },
async ({ topic, content }) => {
const response = await fetch('http://localhost:8080/knowledge', {
method: 'POST',
headers: {
'Content-Type': 'application/json',
},
body: JSON.stringify({ topic, content }),
});
return {
content: [{ type: 'text', text: `Stored: ${topic} - ${content}` }],
};
}
);You find the complete example (which also includes error handling and more tools) on GitHub. You can find even more examples in the official MCP servers repo and learn more about the TypeScript SDK here.
In the above example, the MCP server is reaching out to another backend API (http://localhost:8080/knowledge) to store some knowledge generated by the LLM. That backend API could be controlled by you or some third-party service.
Of course, you could also build a MCP server that doesn't need to interact with any API at all (though, most MCPs likely will). Your MCP could also try to interact with the local file system, for example.
MCP servers like this can be installed into AI applications that support them. Such AI apps are also called "MCP clients" because they're ready to interact with those servers.
For example, Cursor and Windsurf are AI-powered IDEs (and therefore AI applications using LLMs) that act as MCP clients and allow the installation of MCP servers.
Once installed, behind the scenes, the MCP servers will expose system instructions that are injected (e.g., as system prompts) into the LLM chat histories by the MCP clients (e.g., by Cursor). Those instructions describe the available tools and the tokens that should be generated if such a tool should be used.
The MCP client code also handles the extraction of tokens (like WEB SEARCH), possible input parameters (like the search query), and the execution of the tool code (by the MCP server) behind the scenes. It then also feeds the result of the tool call back into the chat history.
You Don't Need MCPs - But They're Useful
So, as described in this article, you don't need MCPs to make tools available in LLM-powered applications. You can instead write your own logic and therefore expose any API you want to LLMs.
But in order to streamline that process, and make it easier for API / tool developers to make their tools available to LLMs, MCPs can be useful.