

Beyond the usual suspects like OpenAI and Google, a very interesting alternative is gaining traction in AI-town: Open Large Language Models (LLMs).
Models like Google's Gemma, Meta's Llama, Alibaba's Qwen, and DeepSeek can be amazing replacements - or at least additions - to proprietary models.
And the best part? You can run them locally on your system, thanks to a technique called quantization, no supercomputer is required!

Related article
Making Sense of Quantization
Quantization is a technique that essentially "compresses" the weights of a LLM, hence allowing it to run on way less (V)RAM than it would otherwise need. This is a game changer for running open LLMs like Gemma, Qwen or Llama locally.
For a long time, interacting with LLMs meant sending prompts via APIs or using AI chatbot apps like ChatGPT. But "open" models change that game entirely. They make their weights/parameters (the training results) available. All you need - and this is the crucial part - is some software to actually run them.
That's where tools like LM Studio and Ollama come into play.
What Exactly Are Open LLMs?
Think of it like this: ChatGPT is a service, built and maintained by OpenAI. You send a query, they process it, and you get an answer. With open models, you host the model yourself (e.g., on your laptop). Tools like LM Studio (which I highly recommend - more on that later) and Ollama provide a convenient way to browse, download, and run these models with ease.
LM Studio comes with a powerful GUI, Ollama is a CLI application but offers plenty of advanced features around model customization.

Course
Local LLMs via Ollama & LM Studio - The Practical Guide
Learn how to use LM Studio & Ollama to run open large language models like Gemma, Llama or DeepSeek locally to perform AI inference on consumer hardware.
Explore courseSo how does it work in practice?
Basically, you download the model weights & architecture - which can be quite large (several GBs), depending on the amount of parameters the chosen model has. There are different file formats for that, GGUF is one of the most common ones.
LM Studio and Ollama handle all the technical complexities.
Why Would You Want To Run LLMs Locally?
Okay, so you can run them locally. But why would you even want to?
Why Not Just Use ChatGPT?
Here's a list of the key advantages:
- Cost-Effective: Forget those recurring subscription fees for many use cases. Once you have the hardware, running the models is essentially free.
- 100% Privacy: This one is huge if you work with sensitive data. Since everything runs on your machine, your prompts and outputs never leave your control.
- Offline Capability: No internet connection? Not a problem. Local execution means true offline AI superpowers.
- No Vendor Lock-in: You're not tied to any specific provider's API changes or pricing schemes. Choose the model that you want, and swap it out if needed.
- Integrate Into Your Tools & Apps: This is where things get really interesting. You can use these LLMs directly in your own local applications, scripts, or development workflows for customized AI tools.
But How Do They Compare To ChatGPT, Google Gemini etc.?
Pretty good!
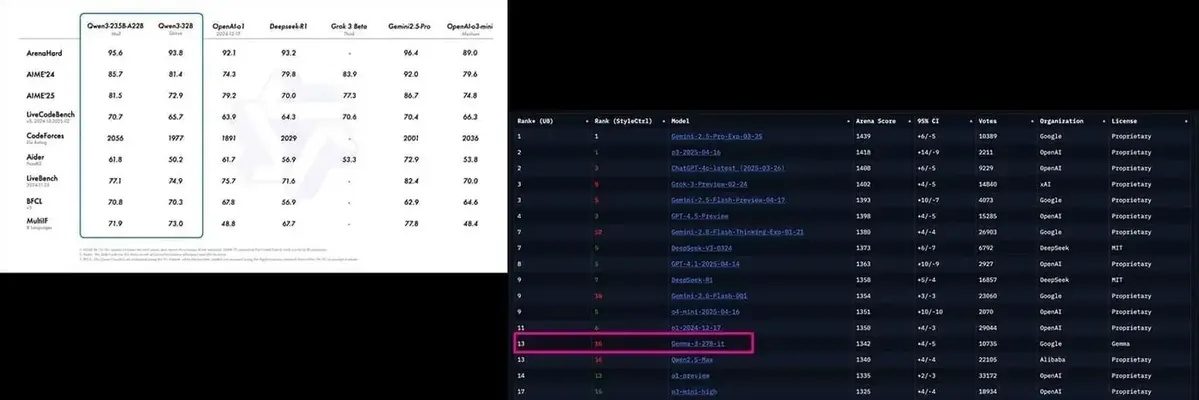
Of course, most of those open models (but not all of them - looking at you, DeepSeek R1!) are way smaller than the models powering ChatGPT or Gemini.
Smaller in the sense of "they have fewer parameters".
For example, Google's open Gemma 3 models ship in 1bn, 4bn, 12bn and 27bn parameter variants.
That 27bn model is the largest one but it's way smaller than the 1tn+ parameters the latest GPT models likely have.
Generally, more parameters equal higher output quality, but that's not the whole story. The training data, architecture, and fine-tuning also play a significant role. There also are diminishing returns when it comes to parameter count.
That's why many of those smaller models do quite well in benchmarks (e.g., Qwen 3 benchmark)
LM Studio & Ollama Make Running Models Locally Easy
If you're new to this world, I highly recommend starting with LM Studio. It has a fantastic GUI (graphical user interface), makes browsing and downloading models incredibly easy, and offers many helpful features and settings to customize your experience.
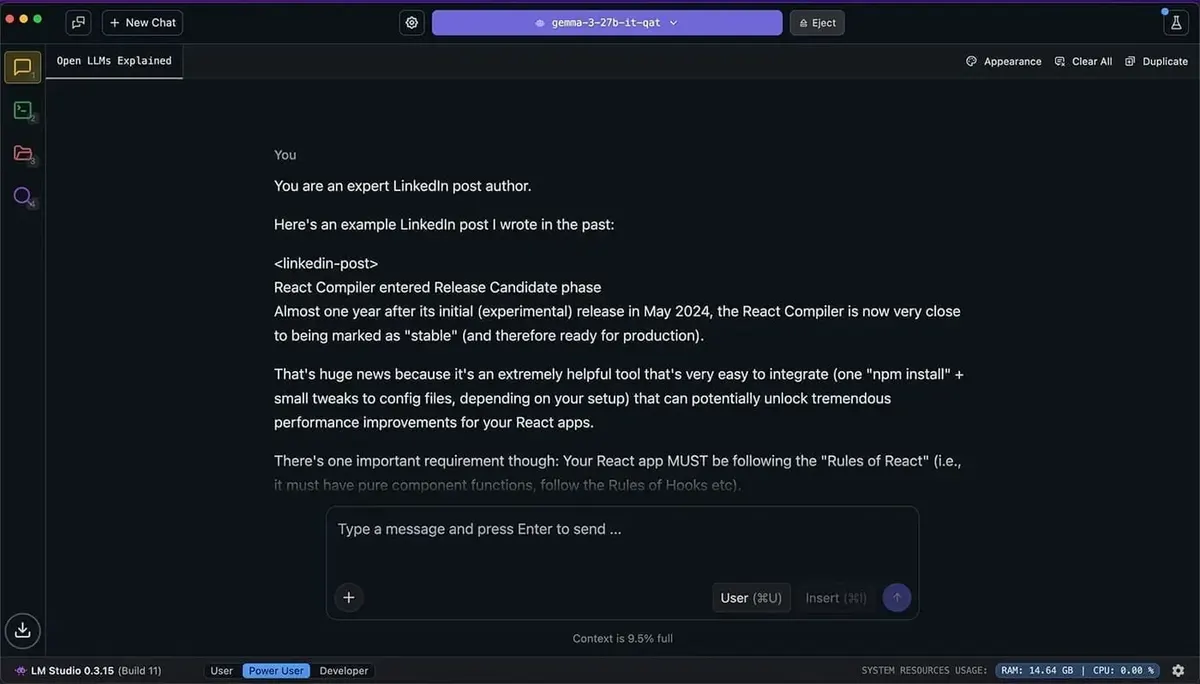
Seriously, it's about as close to "plug and play" as you can get with LLMs. You'll be up and running in a matter of minutes.
Ollama (<https://ollama.ai/>) is another great option (and also free!) but lacks the GUI that LM Studio provides. It does allow you to customize models, though.
In my course, I cover both tools.
Open Models Are A Great Additional Tool
Of course, this does not mean that you should replace ChatGPT, Gemini, Grok, Claude etc. with locally running models.
These open models don't give you that cutting edge performance (and speed) that the big players do.
But I've found open models to be a perfect addition - and often an alternative - to cloud-based LLMs. They give you control, privacy, and flexibility that simply aren't possible with proprietary solutions. Plus, the cost savings can be significant.
And they really shine at tasks like:
- Content Generation / Enhancement: Especially when combined with few-shot prompting.
- Text Analysis / Summarization: Also, because you don't need to upload your PDFs anywhere - 100% privacy!
- Image Analysis: If you're using a model that supports it (like Gemma 3).
- Programmatic Use: Via the locally running APIs exposed by LM Studio and Ollama.
If you're curious about learning more, I recently launched a complete course on open models, LM Studio, and Ollama! You find a link here.